VoroClust is available to Sandians on request. The best way receive permission to access the repository is to reach out to the team via the About / Contact Us page on this website. VoroClust currently has a government-use license, so external government partners can also be given access.
Getting VoroClust
You will need to get a copy of VoroClust. You can clone the Git repo like so:
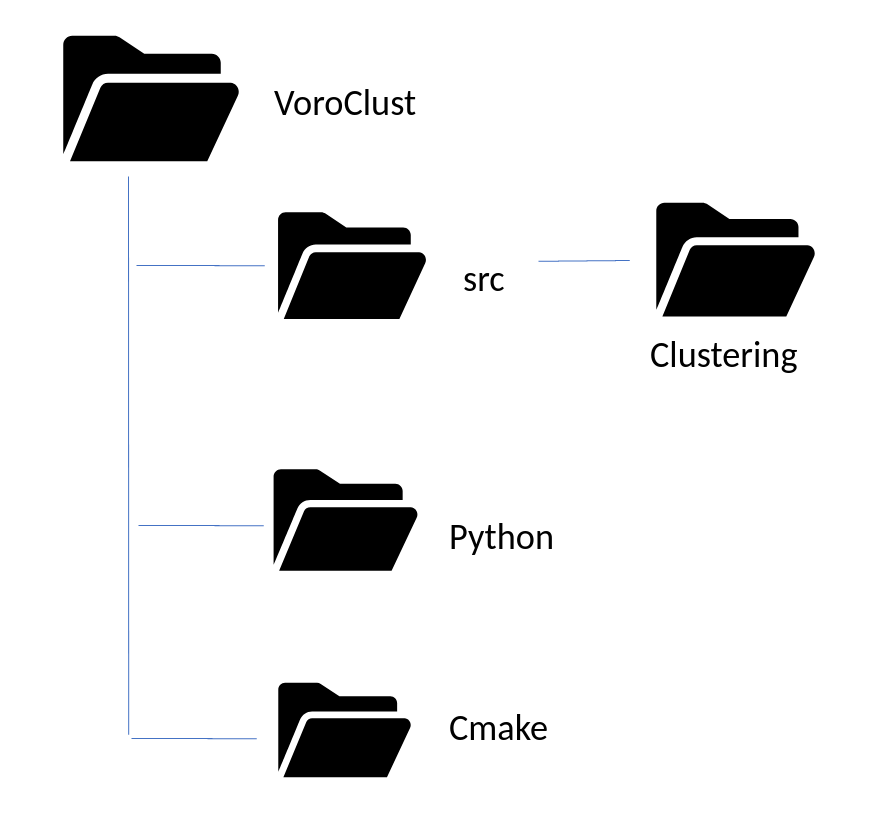
Once you have the VoroClust software, the folder structure will be as follows:
Using VoroClust
There are 2 ways that users can implement the VoroClust software. Users can build the C++ code and produce an executable that they can then run with a config file; or users can install VoroClust as a Python package that they can then import into their Python scripts.
Method 1 – Using with Python
Installation Instructions
The easiest way to use voroclust is with the python package. The package can be built from the repository be moving into the voroclust/python directory and executing the following command:
python -m pip install .
With python 3.10+, this should handle all dependencies automatically. Further troubleshooting information can be found in the repository README.
Usage Instructions
Once the package is installed, voroclust can be imported and used in any python script.
from voroclust import voroclust
import numpy as np
import matplotlib.pyplot as plt
###print full documentation
help(voroclust)
data = np.loadtxt("path/to/data.csv", delimiter=',')
size = data.shape[0]
dimensions = data.shape[1]
vc = voroclust(data.flatten(),
data_size=size,
data_dimensions=dimensions,
radius=.35,
detail_ceiling=.8,
descent_limit=.2,
num_threads=12,
data_tree_filename="")
###Optional: skips sphere generation, to allow faster tuning of secondary parameters
#vc.loadSpheres("spheres.bin")
vc.execute()
###Choice of post-processing steps
vc.labelByMaxClusters(4)
#vc.labelNoise(.05)
###Optional: write some data to files which can be loaded on subsequent runs to save time
#vc.writeDataTree("tree.bin")
#vc.writeSpheres("spheres.bin")
data_labels = vc.getLabels()
###plotting results if it's just a 2D dataset
plt.scatter(data[:,0], data[:,1], c=data_labels)
plt.show()
###for higher dimensional data, results can be plotted by reshaping
###and using labels to color pixels of an image
# pixel_rows=628
# pixel_columns=557
# labels_reshaped = np.reshape(data_labels, (pixel_rows, pixel_columns))
# plt.imshow(labels_reshaped, interpolation="none")
# plt.show()
Method 2 – Using as Executable
Build
As an alternative to Python, you can build and run an executable directly. Start by creating a build directory at the root level of the VoroClust project (voroclust/build), and using cmake to build:
cd voroclust
mkdir build
cd build
cmake ..
On linux or MacOS, you can finish the build with:
make
On Windows with visual studio, cmake will have generated a VoroClust.sln file in the build folder. You can finish the build by opening this in Visual Studio, and selecting Build –> Build Solution in the top bar.
You should now have voroclust.exe in your build folder, or child folders depending on settings.
Execute
Once you have the executable, you need 2 things, a data file and configure file. The data file will need to be a .csv file and the configure file will need to end with extension .in.
VoroClust expects a csv datafile where each row is an n-dimensional data point. The data file will look similar to this one:
And the configure file should look similar to this. The format is just a simple set of key-value pairs.
The parameters include-able in the configure file are:
DATA_FILE – This parameter specifies which data file you want to use
OUTPUT_FOLDER – This allows user to choose where the output is written to
RADIUS – The radius of spheres used to cover the domain
NOISE_THRESHOLD – Determines the fraction of data points which will be labeled as noise in a post processing step
DETAIL_CEILING – Value between 0 and 1. Controls clustering propagation.
DESCENT_LIMIT – Value between 0 and 1. Controls clustering propagation. DETAIL_CEILING should be greater than DESCENT_LIMIT.
FIXED_SEED – Set a fixed seed. Defaults to -1 (random operation)
NUM_THREADS – Number of OpenMP threads to use. Defaults to 1.
READ_DATA_TREE_FILE – To save time, we can load the data’s Kd-Tree from a .bin file, rather than recomputing it.
WRITE_DATA_TREE_FILE – Write the Kd-Tree to a .bin file for future use.
READ_SPHERE_FILE – To save time, we can load the sphere cover from a .bin file, rather than recomputing it.
WRITE_SPHERE_FILE – Write the sphere cover to a .bin file for future use.
WRITE_DATA_BIN_FILE – Given a .csv DATA_FILE, writes the data to a .bin for reduced storage and faster loading. If this parameter is present, will skip clustering and ONLY write the file.
Using the Executable
Once you have built the executable and you have the config and data file, the command line usage is as follows:
./voroclust config.in
Running this command will produce a file titled something along the lines of data_labels_0.100000_0.850000_0.150000.csv, the significance of the file name being the parameters used during the execution.
Data Format
The VoroClust executable expects a .csv data file as an input. While this is simple and cross-platform, it is not efficient for large datasets. Using the Python package grants significantly more flexibility, as any format that can be loaded and processed in Python can be used. If you can’t use the Python package, there is a configuration parameter WRITE_DATA_BIN_FILE. If it is included in the configuration along with an input .csv and output folder, voroclust.exe will parse the input .csv and write the data out to a much more compact .bin file that can be used in future runs.
Additional Help
If you need any additional help with using VoroClust please do not hesitate to reach out to us.